Deploying a Model
This is an overview of Deploying a Model
How to initiate a model deployment
From the model list
Look for the model you are interested in using and click the deploy button - this will initiate the deployment workflow with the StarOps Agent.
You will also see any currently deployed models here with their inference endpoint
From chat
You can request to deploy a model through the chat box on the home page. Our agent may clarify the model version with you first, but once confirmed you will enter the deployment workflow.
Each deployment workflow history will be retained in StarOps - learn more here Models Page
The deployment workflow
At the start of each model deployment workflow you will be prompted to select your target environment. Your target environment is defined for your organization by the AWS Integration Settings.
Once you’ve selected your environment StarOps will begin checking your cluster dependencies.
Executioin Plan In Progress

Execution Plan Done
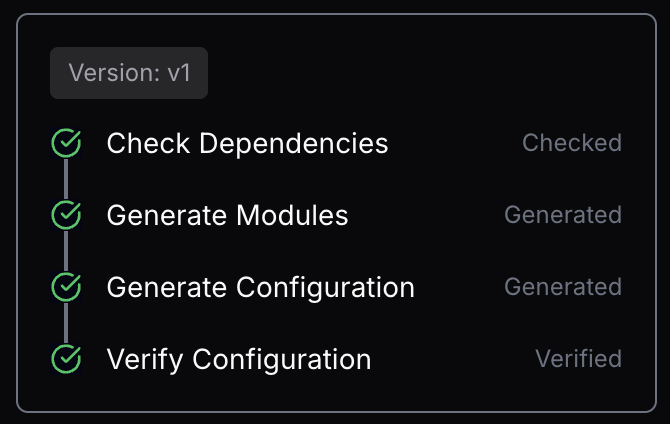
Based on your environment, StarOps will create a deployment plan and generate all the required assets to configure your deployment and infrastructure. You can learn more about how StarOps deploys models here - How It Works.
You can see a summary of each step the agent is taking to prepare your deployment plan at the top of your conversation.
Once the agent has completed its plan you will see a summary of the resources it will create in the conversation panel.

Depending on the results of the dependency check, you may see our agent include deploying the model serving framework, KServe, and required addons. At this time you will also have access to all the generated IAC assets used for your deployment.
Generated assets
The agent will generate IAC assets, in the form of Terraform files that will be used to configure your environment and launch the inference service. The files will appear in the console and you can inspect each file individually. For an overview of key resource settings you can view the config summary.
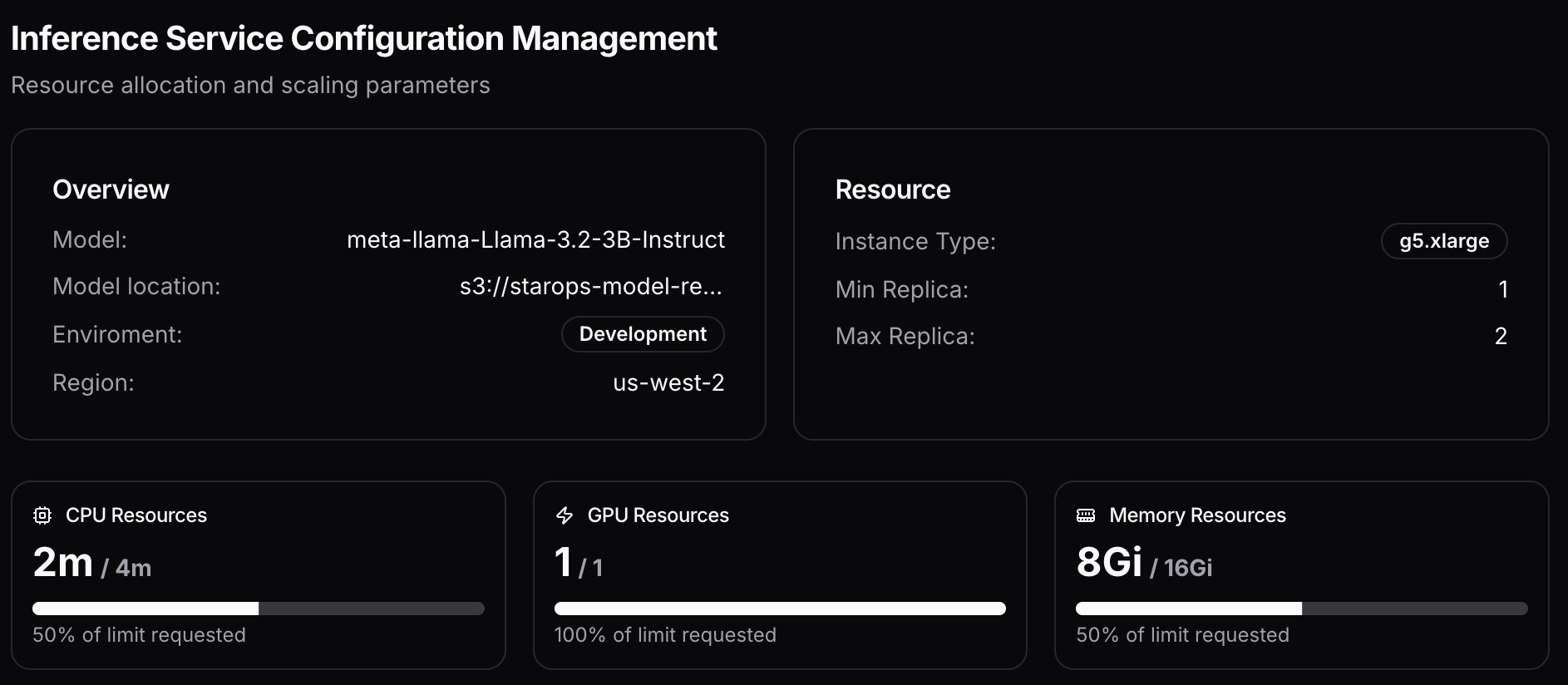
Config summary
This view provides a high level overview of critical model deployment settings contained in the deployment plan. The config summary will appear in the console once all assets and variables are finalized. It will contain: S3 bucket for the model on your VPC Key settings of your inference service, including node instance type, CPU and memory requested/limits, GPU limits, and your deployment’s scaling configurations. Once you deploy this model, the config summary will update to include your ingress and inference endpoint.
Deployment
Once StarOps has planned your model deployment you will have the option to deploy the model and any dependencies to your VPC. You can click the now available deployment button or simply tell the agent to deploy the model via the chat.
Once your deployment starts you will see a summary box appear of each deployment step. Note that depending on model size deployment may take a few minutes, but usually not more than 20. StatOps will run verification on the deployment to ensure all resources have been provisioned and that your cluster is ready.
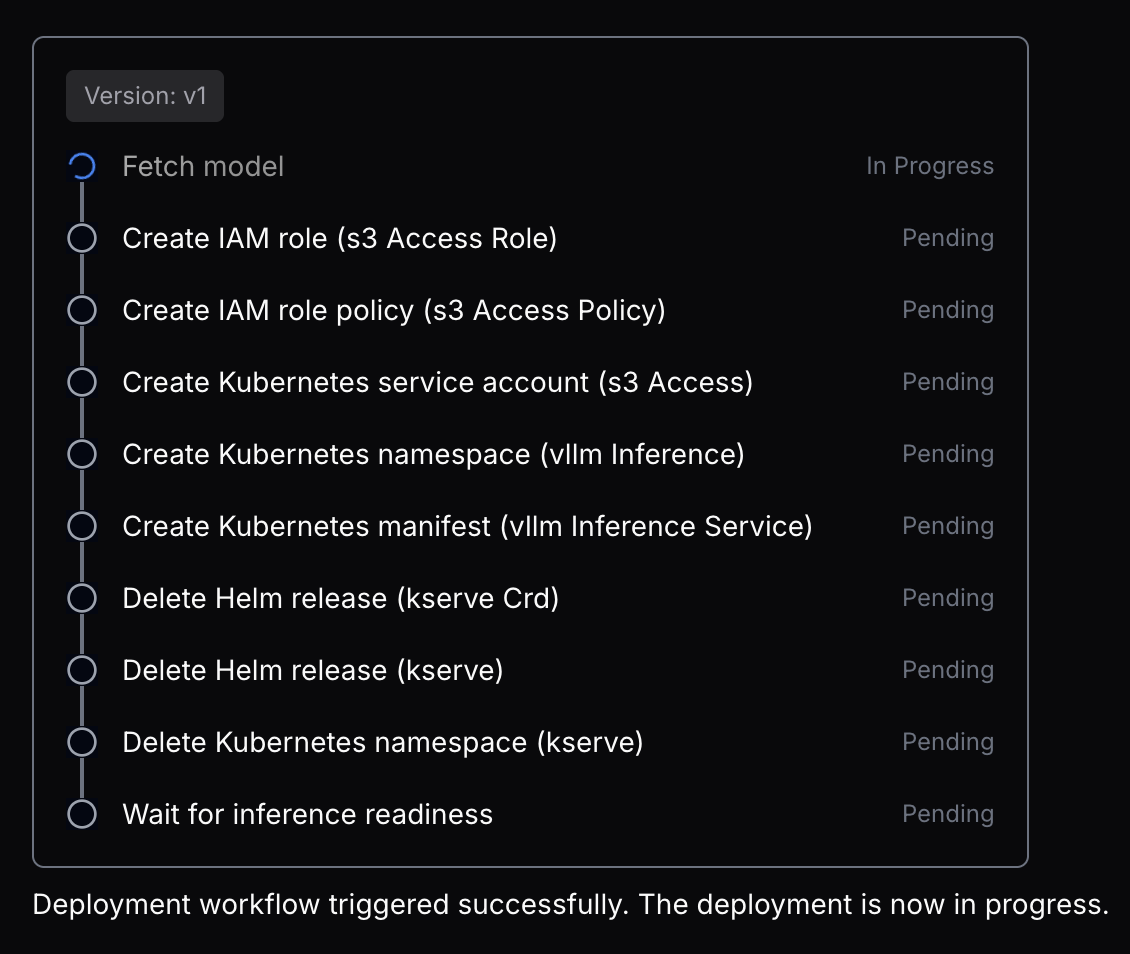
Once completed you will be provided a deployment summary with your configured inference service end point.
You can see deployed models and their inference endpoint next to the models on the models page.